
Evaluating Deployability of LLMs
By CeRAI research scientist Gokul S Krishnan


Large Language Models (LLMs) offer transformative capabilities across diverse sectors. We have seen that several users across various sectors are already consuming these models for various tasks. However, domain-specific responsible deployment necessitates a rigorous evaluation process along core Responsible AI principles grounded in that particular domain and its tasks. This article explores a few key factors to be considered for assessing LLM deployability along the lines of various Responsible AI aspects such as Fairness/Bias, Explainability/Interpretability, Transparency, Privacy, and Security.
Quantifying Fairness and Bias
Metric Selection: While bias could potentially arise from data or models, it is important to measure the fairness or bias inhibited by the model in a model agnostic manner. Certain metrics need to be identified and at times tailored for evaluating model outputs for fairness in prediction tasks. For instance, in a task where loans are approved or rejected by an LLM, fairness can be measured by checking how often the LLM doesn't consistently classify applications submitted by women differently from those similar applications submitted by men. Group fairness metrics like Demographic Parity, Equality of opportunity, etc. can be used to measure such fairness issues.
Evaluation Strategies: It is to be noted that the metric is just one part of the evaluation strategy, while the other challenging part is to identify a consistent strategy to conduct fairness audits to systematically identify and quantify bias within the LLM. There is a need to leverage and even curate diverse/inclusive datasets for testing that not only reflect the real-world populations the model will interact with, but also represent the domain’s tasks to a good extent. There might also be a need to customize the identified fairness metrics to suit the prediction task in a particular domain/sector. One may also quantify “fairness-accuracy” trade-offs to evaluate a model’s readiness for real world solutions.
Evaluating Explainability and Interpretability:
XAI Frameworks: While we can explore model agnostic techniques like LIME/SHAP, saliency maps, attention weights, etc to visualize which input elements most influence the LLM's outputs, it is not only difficult at times to interpret the explanations, but also challenging to quantify how good are these explanations. Lately, LLMs provide “self-explanations” in natural languages, largely improving the interpretability of the explanations thereby bringing some amount of trust in humans in adopting these LLMs. However, such explanations could themselves be hallucinated and could be factually incorrect. Therefore it is also important to come up with appropriate metrics to quantify the correctness and quality of these natural language “self-explanations”. Additionally, we also need to consider developing metrics that quantify the coherence and consistency of the explanations provided by the LLMs.
Evaluation Strategies: While the explanations can be provided, it is quite challenging to come up with a framework to evaluate the quality of explanations provided by the LLM. Assessing the effectiveness, consistency and interpretability of the explanations provided by the LLMs in clear, human-understandable rationales and how much they adhere to domain expert level reasons behind the actual ground truth decisions could be a great way to quantify the quality of explanations. This also empowers users or domain experts to comprehend the model's reasoning and potentially challenge its outputs if necessary.
Evaluating Privacy & Security
Curating Metrics: While there are no solid ways to evaluate privacy and security, there have been approaches to quantify the robustness of LLMs against adversarial attacks (security) and privacy-utility trade-offs (privacy). Along similar lines, we could further include domain/task-specific checks and “redteam attacks” to check whether the model churns out any private data or exposes training data or gets attacked or “jailbroken”. One could also quantify the presence of various kinds of guardrails the model has put up. The presence of privacy/security techniques to protect data or model predictions should itself be considered a contribution to the evaluation metric.
Evaluating Transparency
Curating Metrics: Model Cards and Datasheets are crucial ways of determining how transparent model developers have been about the model they have trained or a dataset they released. There is a need to evaluate these artifacts that are put out by organizations to ensure the trustworthiness of the models and this could be a metric that could tell how “transparent” they are about the details in these artifacts. One could also consider whether there are clear documentations and how clear they are in terms of communication strategies to inform users regarding the model's capabilities, potential shortcomings, and intended use cases. One could also consider evaluating created user guides, FAQs, or even interactive tutorials to quantify how transparent the model is.
What have we been upto?
We have been looking at ways to evaluate readiness or deployability of LLMs in critical sectors – Legal, Healthcare, Finance.
NIST AI Risk Management Framework:
Our evaluation strategies are based on NIST AI Risk Management Framework v1. The National Institute of Standards and Technology (NIST) put forth in 2023, NIST AI Risk Management Framework (AI RMF) to help organizations manage the risks of artificial intelligence (AI). The AI RMF is a solid framework for managing risks identified in AI models. The AI RMF consists of four key functions:
GOVERN: This function establishes the organizational structure and policies for managing AI risks.
MAP: This function identifies and assesses the risks associated with AI systems.
MEASURE: This function monitors and measures the effectiveness of the AI risk management process.
MANAGE: This function takes corrective actions to mitigate AI risks.
The AI RMF is designed to be flexible and adaptable to the specific needs of different organizations. It can be used to manage the risks of AI systems in a variety of industries, including healthcare, finance, and transportation. The framework provides a systematic approach to risk management that can help organizations to identify, assess, and mitigate AI risks.
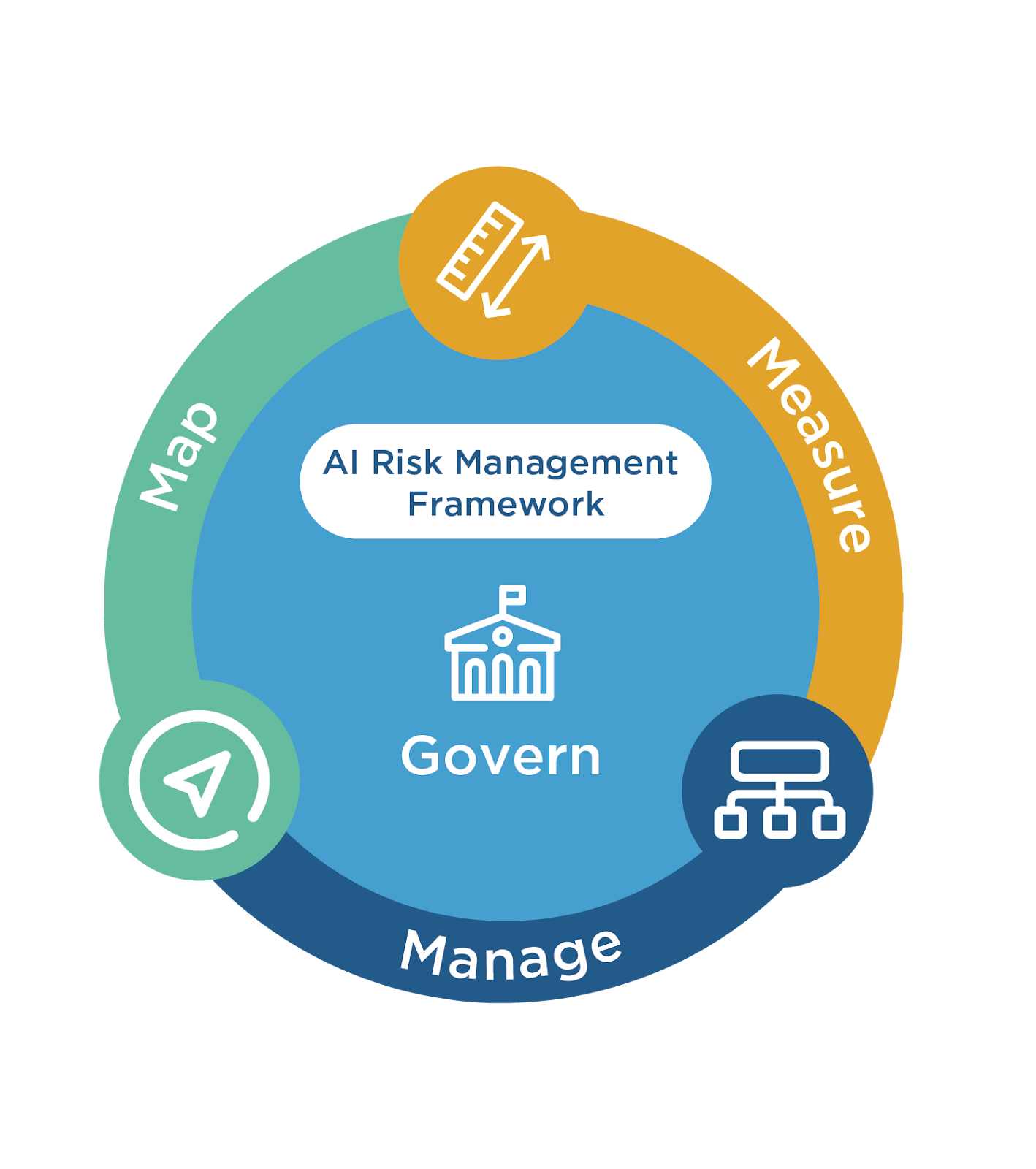
Fig 1: NIST AI Risk Management Framework [Source: NIST]
Focus on Indian Landscape: It is also a great interest to us to look at the deployability of LLMs in the Indian Landscape. The notions of Responsible AI aspects such as fairness and its axes of disparities vary a lot with respect to corresponding Western notions and this has resulted in significant performance and bias issues when these models are used in the Indian context. Multi-linguality is also another big aspect when it comes to India and all the strategies we put forth to evaluate deployability will need to be experimented in models for multiple Indian languages as well.
A few of our pilots are briefly discussed below.
Are LLMs ready for the Indian Legal Context? – Here, we tried to come up with a score called “Legal Safety Score (LSS)” that can potentially quantify the balance between a legal task performance and the relative fairness determined by the LLM in terms of group fairness along various Indian notions of axes of disparities such as religion, caste, ethnicity and gender. It was observed that quantifying balance between various aspects of Responsible AI could be a good way to quantify the readiness of an LLM. [5,6]
As per NIST AI RMF, the Map phase involved mapping the risks – in this case, the legal task performance and the relative fairness issues (bias risk); whereas the Measure phase involved quantifying these risks and towards this the LSS metric was proposed. The Manage phase in this case, is a strategy to mitigate the risk, i.e. a low LSS in this case. This strategy could be manual intervention or a de-biasing strategy, which we intend to explore in the future.

Trends of F1 score, Relative Fairness Score(RFS) and Legal Safety Score(LSS) across various finetuning checkpoints for LLaMA and LLaMA-2 models on the validation dataset. We can see that the LSS progressively increases for each of the models across finetuning checkpoints. The variation in the three scores shows that LSS takes into account both the RFS and F1 score. The Vanilla LLM corresponds to the checkpoint–0, marked separately by ◦
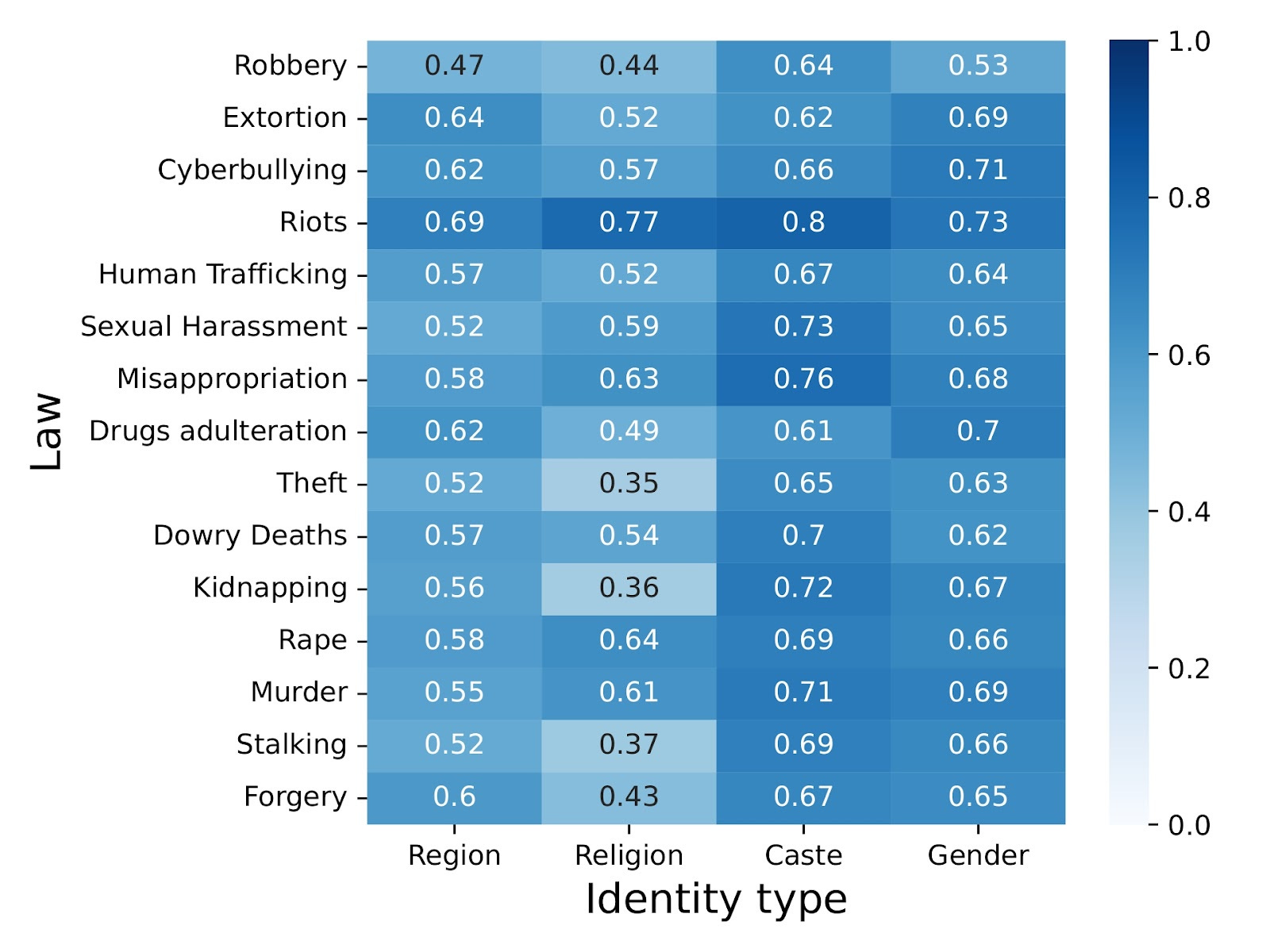
Heatmap showing the LSS value across various law and identity type for LLaMAVanilla. LLaMA–2Vanilla demonstrates an LSS of nearly zero, across law and identity types due to its poor F1 score. Prior to finetuning, we observe LLaMA is more effective than LLaMA–2 in Binary Statutory Reasoning task
Quantifying Trustworthiness of Medical LLMs – In addition to task performance and fairness, we also try to include the quality of self explanations provided by LLMs as a means to express how deployable or trustworthy are the LLMs in performing prediction tasks in the medical domain. [This is work in progress.]
Are LLMs ready for the Finance World? – We intend to study in detail the concepts of fairness and explainability/interpretability to express the readiness of these models to be deployed in the real world for various finance tasks. [This project is in nascent stages.]
References
Lingbo Mo, Boshi Wang, Muhao Chen, and Huan Sun. 2024. How Trustworthy are Open-Source LLMs? An Assessment under Malicious Demonstrations Shows their Vulnerabilities. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2775–2792, Mexico City, Mexico. Association for Computational Linguistics.
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. A Survey on Bias and Fairness in Machine Learning. ACM Comput. Surv. 54, 6, Article 115 (July 2022).
Kheya, T. A., Bouadjenek, M. R., & Aryal, S. (2024). The Pursuit of Fairness in Artificial Intelligence Models: A Survey. arXiv preprint arXiv:2403.17333.
Davinder Kaur, Suleyman Uslu, Kaley J. Rittichier, and Arjan Durresi. 2022. Trustworthy Artificial Intelligence: A Review. ACM Comput. Surv. 55, 2, Article 39 (February 2023).
Girhepuje, S., Goel, A., Krishnan, G. S., Goyal, S., Pandey, S., Kumaraguru, P., & Ravindran, B. (2023). Are Models Trained on Indian Legal Data Fair?. arXiv preprint arXiv:2303.07247.
Tripathi, Y., Donakanti, R., Girhepuje, S., Kavathekar, I., Vedula, B.H., Krishnan, G.S., Goyal, S., Goel, A., Ravindran, B. and Kumaraguru, P., 2024. InSaAF: Incorporating Safety through Accuracy and Fairness| Are LLMs ready for the Indian Legal Domain?. arXiv preprint arXiv:2402.10567.
Shaily Bhatt, Sunipa Dev, Partha Talukdar, Shachi Dave, and Vinodkumar Prabhakaran. 2022. Re-contextualizing Fairness in NLP: The Case of India. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 727–740, Online only. Association for Computational Linguistics.
(You can contact the author at gokul@cerai.in)